Microservices for the Benefits, Not the Hustle
From time to time I hear people saying “It can not be scaled because it is a monolith, we need to rebuild it as microservices”. If you think this way, read on, this article is for you.
Making a system scalable — or cheaper to scale — is the first benefit that comes to mind when you think about microservices. Unfortunately, this is not even true until you reach a certain load on your system. And in most cases, this break-even point is far away. The root cause for this misunderstanding is the fact that companies that promoted microservices indeed have a huge load (e.g. Netflix, amazon, Twitter) but this is probably not the case for the rest of us.
But still, I’m a believer in microservices, even if you do not have a big load on your system. I hope this article helps you to understand all the other benefits and how to make the most out of it.
What is important to understand is, that you have to define and rank your requirements before building the architecture. Depending on the ranking of your requirements the best microservice architecture might look completely different!
This article explains the purposes and risks of microservice architectures. It further gives some hints on how an architecture must look to met reusability and maintainability requirements. At some points, it also compares microservice to traditional service-oriented architectures (SOA).
Purpose 1: Minimize Costs of Change
Minimizing the costs for new or changed requirements is (in my opinion) the major benefit of the microservice architecture style. This benefit comes directly from the “single responsibility principle”. The microservices pattern prescribes radical rules to enforce this principle to maximize its benefits.
To prevent code is added where it doesn’t belong and to ensure changeability, the microservice pattern recommends that:
- different responsibilities are placed in different services
- each service has its code repository
- each instance of a microservice is executed as a dedicated process
- inter-service communication is only allowed through a network connection. In addition, services must use their official API to talk to each other: it is not allowed that one service to access the data of a database that has been written by another service. Each service must have its own logical database schema!
- the protocol used for communication must be technology agnostic (interoperable). This means a service should not assume that another service is written in a specific programming language.
- choreography should be preferred over orchestration
Some of these principles might remind us of a traditional service-oriented architecture (SOA). Each microservice architecture is a service-oriented architecture, but not the other way around. There are some discussions about whether microservices are SOA done right.
The difference that makes a service-oriented architecture a microservice architecture is, you guessed it, a smaller service size and lightweight protocols. The smaller service size is a result of applying the first principle from the list above: place different responsibilities into different services.
Later in this article, we’ll have a closer look at how to decide which responsibilities go together into one service and which should be better separated. For now, we assume that a well-done microservice architecture is in place and examine how each of the rules above contributes to lower costs of change.
Enforced cohesion because of hard system boundaries
Cohesion in software architecture is a measure of how related the responsibilities of a module are [SAiP, S. 121]. So when a module has responsibilities that are strongly related to each other, this module has a high cohesion.
Attention: Don’t fall into the trap and put related responsibilities into different services!
Because different responsibilities are placed in different code repositories, it is much harder to place new code into modules to which they don’t belong by design. This is a common problem in traditional applications:
Developers will eventually ignore or oversee the boundaries of subsystems due to time pressure or insufficient understanding of the larger code base. As a consequence of that, related logic is distributed across system boundaries and it is much harder to maintain and extend the software. Subsequently, the test suite gets also more complex and this is another reason why it’s harder to ensure that everything is still working after a code change.
Lower coupling because of high cohesion
“Low coupling often correlates with high cohesion, and vice versa” [SADCW]. In a well-designed microservice architecture the dependencies between services are minimized. One reason for that is the same as for the enforced cohesion:
It is hard for developers to introduce new communication paths without talking to the developers of the other services. Even if there is only one developer involved, he will be more thoughtful in introducing new dependencies between two services than between modules within the same code base.
Lower coupling because of choreography
Another driver for lower coupling is that in a microservice architecture, choreography is preferred over orchestration. When a service-oriented architecture uses an orchestration pattern for communication, there are point-to-point connections between the services. Point-to-point means that one service calls the API of another service which results in a web of communication paths between all services. Integrating, changing, or removing services from this web is hard since you have to be aware of each connection between the services.
On the left site, an orchestration with point-to-point connections is shown.
On the right site, a choreography pattern is shown where each service waits for events to act on.
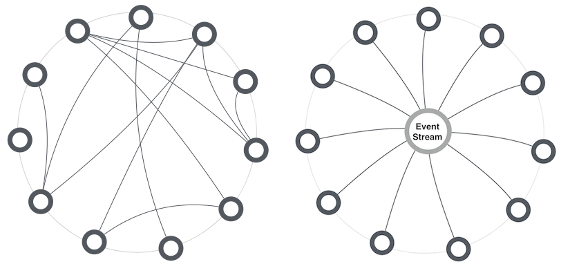
Applying a choreography pattern means that one service doesn’t talk to another service to instruct an action. Instead, each service observes its environment and acts on events autonomously. In real life, this looks like this:
Services are connected to a message bus and subscribe channels they are interested in. Once an event series occurs that matters to the service, the service performs the appropriate action. Now it is easy to add new services to the architecture; You simply have to connect them to the message bus. In the worst case, you must ensure that the other services emit the events that the new service requires. However adding additional events or extending the payload of existing events won’t break existing logic.

Building Microservices by Sam Newman, O’Reilly
Note: When it comes to create/read/update/delete entities the REST protocol should still be a consideration. The service that handles the REST call could then trigger an event that a new entity was created/updated/deleted.
Applying another rule from the list above will result in an even lower coupling: When technology-agnostic protocols are used, different services can be developed in different technologies. So it is possible to pick the best-suited technologies for each service/team.
In the end, a lower coupling allows to replace, remove, or adding new services when requirements change without having the fear that some communication paths have been overseen. So, a lower coupling allows us to make changes to the architecture at a later stage with less effort.
Smaller and cleaner code bases because of separated services
Each service has a small code base and so it is easier for developers to extend or modify a service. Even when a developer hasn’t worked on a service for a while or when a developer is new to the project, the smaller code bases make it possible to be productive right from the beginning.
More source code causes many more errors

In addition, removing dead code to clean up the code base is much simpler in smaller code bases. In traditional applications, developers are worried about removing unused code because they fear side effects. Furthermore, because of the simplicity, the likelihood of introducing errors is also reduced.
The final point of smaller code bases is that the IDE loads faster :)
Smaller teams because of smaller code bases
The people who develop and maintain a service can be organized into small teams where each team maintains and/or operates one service (or a small set of services). Smaller teams minimize management overhead within the teams and will increase productivity dramatically.
Interim conclusion
Because a microservice architecture is made for adding requirements at any time this architecture style is a very good fit for agile development processes. It is possible to implement a minimum viable product, deliver it to the user, and then extend the system over time.
“Applying a microservice architecture is not about building the perfect system instead it is about building a framework in which a good system can emerge over time as the understanding grows.” [bms, S. 15]
However, a still existing problem is that responsibilities are assigned to the wrong service by design. When it comes to designing a microservice architecture many people don’t know how to divide a monolithic problem into multiple (micro)services. And, when the services are too big or too small, the advantages are gone and problems arise. This then bothers developers and also the managers who decided to invest in this architectural style.
Hint: Making services too small is a common pitfall. This antipattern is called “nanoservices”.
So, let’s have a look at the most asked question in discussions about microservices: How small a service should be? The following section “Encourage Generalization, Replaceability and Reuse“ should give you an idea of how to approach this problem.
Purpose 2: Encourage Generalization, Replaceability and Reuse
In microservices, the lessons learned from SOA are applied to fulfill the promise of reuse.
Reusing services is an old idea and in service-oriented architecture (SOA) this is a fundamental goal. The microservice architecture style promotes the following principle to reach the best reusability for a single service:
- Build smaller services doing one thing well. This is similar to the rule from the section above: Different responsibilities should be placed in different services.
A typical show stopper in a discussion about reusing an existing service is its complexity and that the existing solution does much more than is required. Often you hear statements like “This is a simple problem we better build our solution instead of learning how to use an existing one”. To make things worse complex software goes along with complex documentation. How often did you hear a colleague complaining about documentation?
There are some rules of thumb out there how small a microservice should be:
- “ The service can be rewritten and redeployed in 2 weeks. “, Jon Eaves
- “ It must be possible to feed a team that maintains a service with two pizzas. “, Werner Vogels
These are good rules of thumb and one could argue that these are extreme examples. Two weeks to rewrite a service is a desirable time range but according to the pizza example, I must always work in a one-man team.
To get a well-designed microservice architecture we should not ask how big a service should be, instead, we should ask: which responsibilities should go into the same service?
My opinionated answer to this is that responsibilities should be grouped in a way so that the amount and size of domain-specific services are minimized. Domain-specific services, in this context, are services that are specific to the problem domain, and that it’s unlikely to find a scenario for reusing them in other projects.
Conversely, this means that the amount of reused or reusable services should be maximized.
To master that challenge, I like to think of two dimensions of decomposition.
Decomposition Dimension 1: Actions on Entities
Actions that require access to the same database records should go into the API of the same service. For example, creating, reading, updating, and deleting an entity (e.g. a user) should be provided by the API of the same service.
Recap: It’s a no-go that more than one service accesses the same database since it breaks up cohesion (see section ‘Purpose 1: Minimize Costs of Change’). When a service requires information about service B, service A must use the API of service B.
Furthermore, entities that have a strong relation to each other are good candidates to be managed by the same services. From the perspective of reusing a service: When you can’t think of a scenario where you use one entity without the other, it’s an indication that those entities should be better managed by the same service.
Decomposition Dimension 2: Aspects of an action
Just because an action is provided by the API of one service it doesn’t mean that every aspect of that action must be executed by that service. It is often possible to decompose a domain-specific action into one or more generic actions. In such cases, we should think to leave those aspects of an action to other services.
A simple example: When a new user signs up at an online shop, an email to this user should be sent. It is a good idea to use an email service to send out those emails. Why? In case the layout of all emails should be changed each service that sends emails must be changed. Sending emails is such a generic problem that there are tons of services out there that can be reused.
A more complex example: When a customer of an online shop views a product the shop system should remember this to generate user-specific advertisements. In this example, we have a service that manages products. Putting the logic to generate user-specific advertisements would blow up the complexity of the product service. Instead, we should do research on which off-the-shelf software can perform such user-specific advertisements and use this system along with the product service. Whenever product information gets requested by a user the product service will notify the advertisement system. FYI: When a user opens a page on Amazon about 200 services are called to perform this action (see [WV]).
Another example: Imagine a fitness tracker wristband that records and analyzes your vitality. Because of the limited disk space and computation power, it sends your vitality data (and maybe your current position) to a microservice architecture. One service acts as an endpoint and is responsible for receiving the data records from the wristbands. To keep the first service simple, this service is just responsible to receive and dispatch the data records. To store and analyze the heart rate we need something like a “heart rate service” that is able to calculate the average heart rate of a given time period in the past (because we want to display this information to the user). Making a generalization step before implementing a heart rate service can save us a lot of work. The heart rate service is a time series database that can be used off the shelf.
Purpose 3: Increase Operations Efficiency
In sum, the footprint of a microservice architecture is usually bigger than the footprint of a monolithic application. This is because, in a microservice architecture, each service must run as a separate process. This means each instance of a service requires its own runtime (e.g. JVM, Ruby interpreter, etc.).
But there is a break-even point when it comes to horizontal scaling. When scaling a monolithic application horizontally you must install the whole monolith multiple times. This is a kind of waste because often only a small part of the application becomes the bottleneck. With a microservice architecture, you can only scale those parts that actually have performance issues. For systems under constant high load, the hardware resources are cheaper when a microservice architecture is in place.
Risk 1: Increase Operations Complexity
One disadvantage of the microservice architecture is obvious: It is necessary to operate many more applications than just one or two. Mature organizations use container (e.g. Docker), PaaS (e.g. Cloud Foundry) technologies, and continuous delivery methodologies to mitigate this drawback.
Risk 2: Distributed Monolith
In case your architecture has a bad cohesion you will multiply all problems by distributing your application across different microservices (see [JS]).
External Sources
[SAiP] Len Bass, Paul Clements, Rick Kazman; Software Architecture in Practice, Addison Wesley
[bms] Sam Newman; Building Microservices, O’Reilly
[SADCW] John W. Satzinger System Analysis and Design in a Changing World, Key Facts
[WV] Talk; Werner Vogels; Amazon and the Lean Cloud
Blobpost; Jon Eaves; Micro services, what even are they?
Blogbost; Carl Erickson; Small Teams Are Dramatically More Efficient than Large Teams
Blogpost; Jean D’Amore; Scaling Microservices with an Event Stream
Blogpost; Jason Bloomberg; Are Microservices ‘SOA Done Right’?
Webpage; agilemodeling; Examining the Agile Cost of Change Curve
Tweet of an unknow talk: https://twitter.com/mmrichards/status/602949000690466816
[JS] Webpage; Jan Stenberg; Microservices Ending up as a Distributed Monolith
